
IBM FlashSystem は、高いパフォーマンスや強固なセキュリティを求めている組織にとって理想的なオールフラッシュ・ストレージです。
NVMe に対応し独自技術IBM FlashCoreテクノロジー搭載により、きわめて優れた処理能力でデータからの価値創造に貢献します。
お客様満足度も高く、大手B2Bピアレビュープラットフォームである TrustRadius の「エンタープライズ向けフラッシュ・アレイ・ストレージ・ソリューション」部門で2022年もトップ評価賞を獲得しています。
FlashSystem には IBM Spectrum Virtualize という柔軟性の高いストレージ・ソリューションが搭載されており、HyperSwap(可用性)、データ保全(データコピー)、データ移行(無停止でのボリューム移動)、ストレージ仮想化、ストレージ効率化(EasyTier、データの削減・圧縮)など、多くの機能が実装されています。
これらを活用することで、オンプレミス/オフプレミス、またはその両方の組み合わせで新しいワークロードと従来のワークロードに対応するブロック・ストレージ・サービスを迅速に展開することができます。
今回は「もっと活用したいIBM Spectrum Virtualize」をテーマに、カギとなる機能とお客様にお勧めする理由を解説します。
| 目次 |
|---|
シンプルかつスマートにストレージの可用性を高めるHyperSwap
高性能なストレージは、高可用性を求められる状況で採用されるケースが多いものです。
障害、災害、サイバー攻撃に遭ったとしても、ビジネスを止めることは許されない。そのような場合には、ストレージにおいても万一の場合でも稼働を継続できる工夫が必要です。
ストレージの高可用性を実現する手段は様々あります。
例えば、OS やアプリケーションの持つデータ二重書き機能を活用することです。
ただし、二重書き機能を持つ OS やアプリケーションは限られるため、冗長化できないデータも出てきます。また、この方法はサーバのリソースを消費するとともに、OS とアプリケーションソフトウェアそれぞれの二重書き機能を利用するとすれば管理が複雑になります。
もう1つの方法として、ストレージ・レプリケーションを活用する方法もあります。
しかし、AストレージがダウンしたときにBストレージに自動的に切り替えるようにするには、スクリプトの作りこみが必要です。また、切り替え時にはダウンタイムが発生します。
このように、メリットもあるがデメリットもあるという従来のストレージ高可用性ソリューションに対して、IBM Spectrum Virtualize では真に堅牢なストレージ基盤を構築するためのソリューションを提供しています。
それが、HyperSwap です。
HyperSwap はアクティブ-アクティブの HA構成で、片系統に障害が発生してもダウンタイムなしにデータへのアクセスを継続できます。
もう少し具体的に見ていきましょう。
HyperSwap
HyperSwap では、4ノード、2 I/Oグループでストレージクラスターを構成します。
グループ0のストレージには、Aサーバ向けのプライマリデータボリュームとBサーバ向けのセカンダリデータボリュームを持ちます。逆にグループ1のストレージには、Aサーバ向けのセカンダリデータボリュームとBサーバ向けのプライマリデータボリュームを持ちます。
つまり、データをたすきがけに持つことで片系統の障害発生に備えます(図1)。
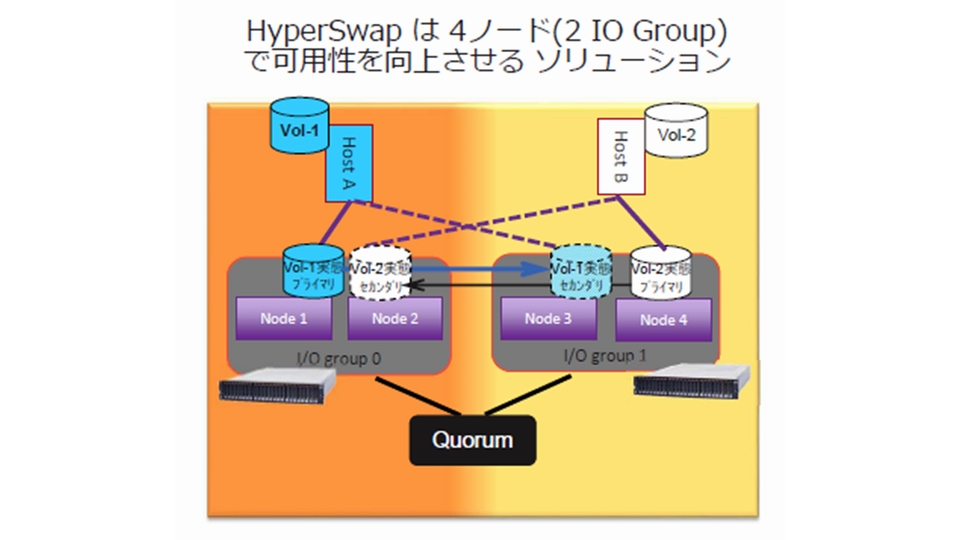
グループ0とグループ1の間には、外部ディスク装置あるいは IP Quorum というストレージの死活監視役を置きます。
これは、グループ0とグループ1から定期的に発信される “正常に動いています” という信号を仲介します。
外部ディスク装置の場合は両方の信号がここに蓄積されるため、グループ0とグループ1それぞれでその信号を確認します。
IP Quorum の場合はグループ0から来た信号はグループ1へ、グループ1から来た信号はグループ0へと相手方へ送信します。
この信号が途絶えたら相手方がダウンしたと判断し、自分の持つデータボリュームをプライマリに昇格させて動かします。
HyperSwap を利用すると、ストレージ筐体全体がダウンしてしまったというときにも問題なく業務を継続できます。
また、ストレージ側で自動切り替えを実施するため処理の作りこみが不要、さらに、サーバ側に専用ソフトや特別な設定は不要で、マルチパス・ドライバーさえ導入されていれば構築可能です。
Remote Copyは機能が改善されIBM Global Data Platformへ
一方、業務によってはそこまで業務継続性にこだわる必要はないというケースもあるかもしれません。
データさえどこかに確保できていれば体制を整えてからそのデータを持って立ち上がればよい。そのような発想のシステムに適しているのが、Remote Copy機能です。
これは、文字どおり離れた場所に設置したストレージにデータをコピーするというものです。
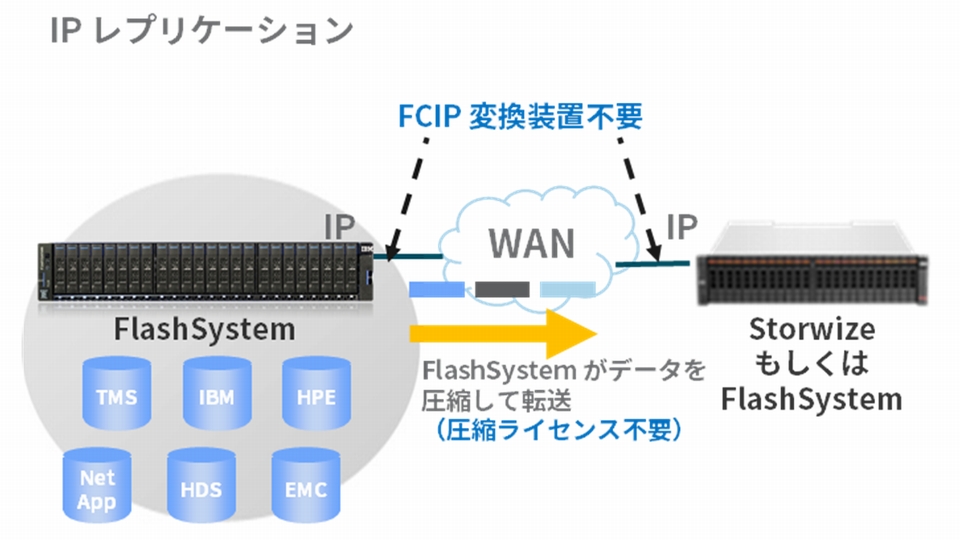
具体的に2つの方法があり、1つが Fibre Channel経由のレプリケーションで、もう1つがネイティブIPレプリケーションです(図2)(図3)。
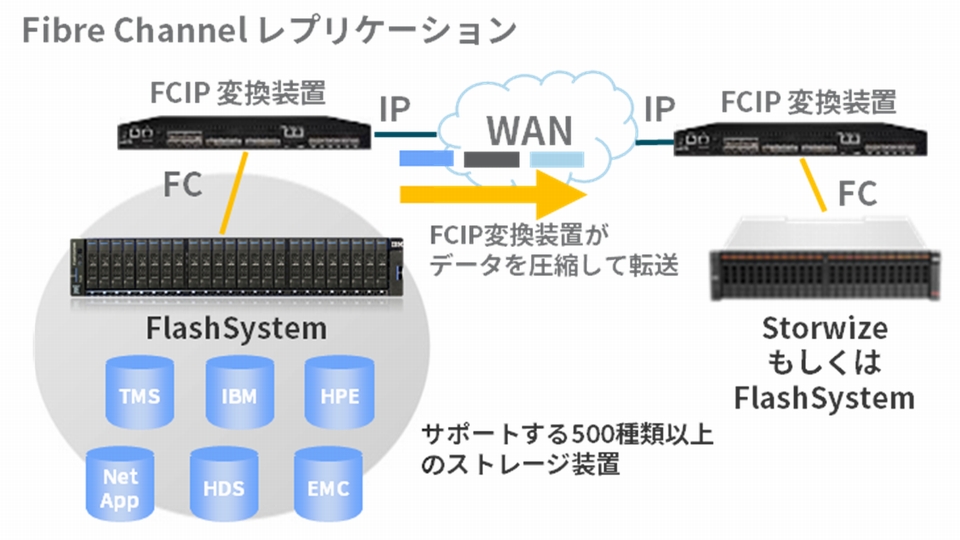
Fibre Channel経由のレプリケーションの場合、コピーを実行したい2台のストレージの間に FCIP(Fibre Channel over IP)変換装置をそれぞれ設置します。
これがデータ圧縮を実施し、リモートサイトのストレージへデータを転送します。
FCIP は TCP/IP上に Fibre Channel を流すプロトコルで、長距離接続の場合に利用します。
ネイティブIPレプリケーションの場合は、FCIP変換装置は不要です。ストレージ自身がデータを圧縮して転送します。
これまで Remote Copy では、データを転送するストレージとデータを受信するストレージの両方に同じ設定が必要でした。
すなわち、データを転送する側の設定を変更したら受信する側も同じように設定変更が必要でした。
しかし、新しく登場した次世代データ基盤 IBM Global Data Platform(GDP)のアーキテクチャに従えば、データ転送側のストレージ設定を変えると受信側の設定も自動的に変更されます。
また、一定の割合で発生していたデータ転送エラーの割合も改善されています。
これらにより、運用現場では管理負荷を軽減することができます。
さらに、これまでハードウェア上の要件が厳しく受信側でのレスポンスタイムが 10mm/sec までしか許容されていなかったものが、GDP で 80mm/sec にまで緩和されました。
これにより、WAN回線がそれほど高品質でなくても適用可能になります。
海外拠点あるいは遠隔の自社拠点間に災害対策用データを置きたいが、専用線は敷設していない。といった条件でも、Remote Copy を検討できるようになります。
ストレート内に聖域を設けるセーフガード・コピー
サイバー攻撃もまた、企業の事業継続を脅かす大きなリスクの1つです。
IBM Spectrum Virtualize では、ランサムウェア攻撃によるデータ暗号化に備えてセーフガード・コピーという機能を提供しています。
これは、ストレージ上のデータが論理的に破壊されることや、変更または削除されることを防ぐ機能です。
利用するには FlashCopy と Copy Service Manager(以下 CSM)のライセンスが必要ですが、これにより堅牢なデータバックアップ運用が実現します。
CSM はセーフガード・コピーの自動化に関わる機能です。
クライアントが提供する仮想マシンや x86サーバ上で動作する外部ソフトウェアで、コピー・スケジュールとバックアップの保存期間管理を受け持ちます。
IBM Spectrum Virtualize がセーフガード・ポリシーを作成すれば、CSM はそれを自動的に発見しそのポリシーにしたがって動作します。
まさに IBM Spectrum Virtualize と CSM が連携して動くイメージです。
セーフガード・コピーがデータを守るしくみは、下記のようなものになります(図4)。
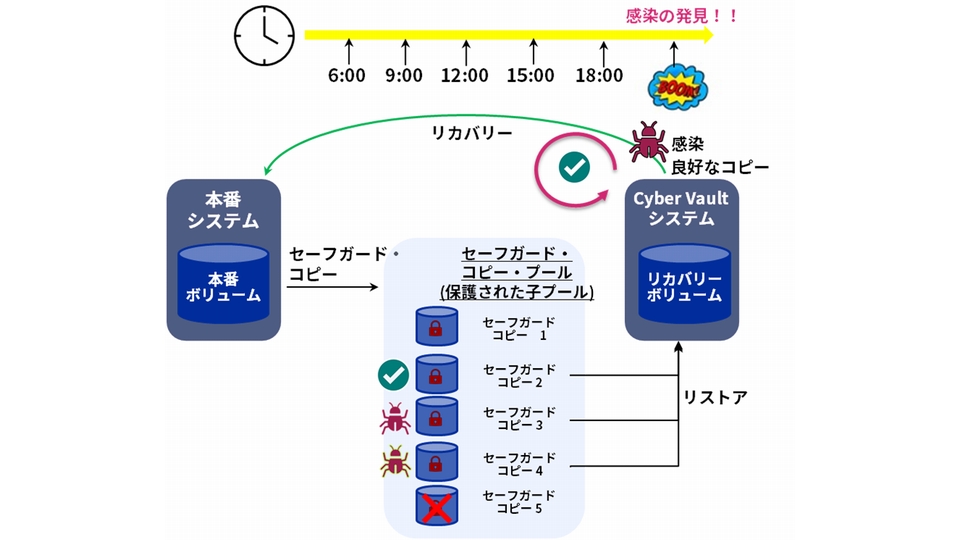
ストレージのデータは、ポリシーにしたがって定期的にセーフガード・コピー・プールと呼ばれる保護された子プールにスナップショットが作成されます。
その時間間隔はデータの特性によって自由に設定可能です。1分ごとにバックアップしたいものもあれば、1日に1回でよいというケースもあるかもしれません。
セーフガード・コピー・プールには最大15,864個のオブジェクト、256世代のバックアップを置くことができます。
また、セーフガード・コピー・プールに置かれるコピーデータはイミュータブル(その状態を変えることのできないもの)です。どのサーバやアプリケーションからもアクセスできません。
ランサムウェア攻撃を受けデータに侵害があったことが、ある時点で判明したとします。
ここで次に起こすアクションは、セーフガード・コピー・プールでコピーデータの世代をさかのぼって、まだ侵害を受けていない時点のコピーデータを見つけ出すことです。
求めるコピーデータが見つかったらCyber Vault
システムとして作成したリカバリーボリュームにリストアします。
そこでリストアされて初めて、サーバやアプリケーションからデータにアクセスできるようになります。
ストレージ内にセーフガード・コピー・プールという “聖域” を設けることによってデータを守るという仕組みは、外部脅威がますます高度化・凶悪化している今日、企業に大きな安心をもたらします。
もちろんヒューマンエラーやハードウェア障害、広域災害によって失われたデータを取り戻す際にも、セーフガード・コピーは有効に働きます。
また、定期的な分析で問題を早期に発見するためのデータ検証や、侵害が判明した際にリカバリーアクションを決定するためのデータフォレンジックにも活用できます。
バックアップシステムを別途構築する必要がなくサーバ運用を簡素化できる、という意味でもお勧めの機能です。
さらに別システムとの連携にはなりますが、データに生じた異常を常時監視するプロアクティブモニタリングを実現することも可能です。
何かあればすぐにアラート通知が送られてくるため、それをフックに健全なコピーをただちに見つけリストアに入るといった、より機敏なアクションを取れるようになります。
まとめ – エヌアイシー・パートナーズがSpectrum Virtualize活用提案をサポート
エヌアイシー・パートナーズではリセラー様における Spectrum Virtualize活用提案について、潜在ニーズを含めたシステム構成支援を始めとして様々な技術的アドバイスが提供可能です。
また取り扱い製品が多岐にわたることから、FlashSystem や Spectrum Virtualize にとどまらず、システム全体の提案支援も行っています。
エンドユーザーの抱える課題を解決するための方策を、弊社はリセラーの皆様とともに考え導き出していきます。
ぜひ、お気軽にご相談ください。
お問い合わせ
この記事に関するお問い合せは以下のボタンよりお願いします。
関連情報
- IBMストレージ製品(製品情報)