
皆さま、こんにちは。てくさぽBLOGメンバーの岡田です。
前回ブログ”VMware on IBM Cloudでクラウド化の提案してみませんか”の第2弾として、前回ブログにも記載しましたVMware on IBM Cloudの優位性について詳細をご紹介します。
VMware on IBM Cloudの優位性を理解いただくことで他クラウドとの比較検討の際の参考にしていただければと思います。
日本を含む世界中40拠点以上のデータセンターで利用可能
各国にあるIBM CloudデータセンターでVMware on IBM Cloudを利用できるので利用要件に合わせて最適な場所を選択できます。日本も含まれているので、仮想サーバーを日本国内に置く必要がある要件の場合でも利用できます。
また、利用環境であるベアメタルサーバーは全世界で10年以上の提供実績がありますので、安心して利用できますね。
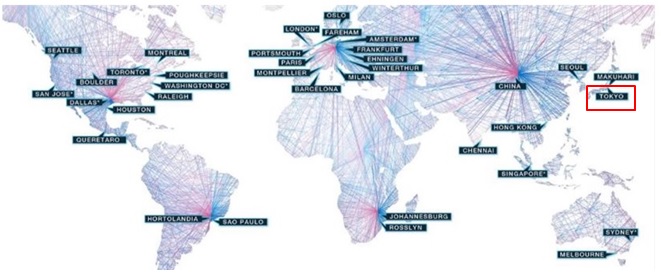
各データセンター間の高速回線を無償で利用可能
これはIBM Cloudそのものの特長ですが、なぜVMware on IBM Cloud環境でメリットがあるのでしょうか。
異なるデータセンター間での仮想サーバー同士の連携や遠隔地保管、災害対策構成などを取る場合、必ずデータセンター間で通信が発生します。このときデータセンター間の通信が無料のため通信料金を気にしないで利用できるので、コスト面で大きなメリットになりますね。
VMwareの管理者権限を保有可能
VMware on IBM Cloud でデプロイされた環境は、オンプレミス環境と同様にハードウェア、ソフトウェアの管理者権限がありますので、これまでの運用要件やスキルを活用しながらVMware環境をフルコントロールしたい場合に最適です。つまり場所がオンプレミスからクラウドに移っただけで他は何も変更を意識せずに運用することができるのですね。
逆に、クラウド移行を機に運用を任せたい場合はIBMのマネージドサービスを利用することも可能です。
要件や規模に応じた複数のデプロイメント方式を提供
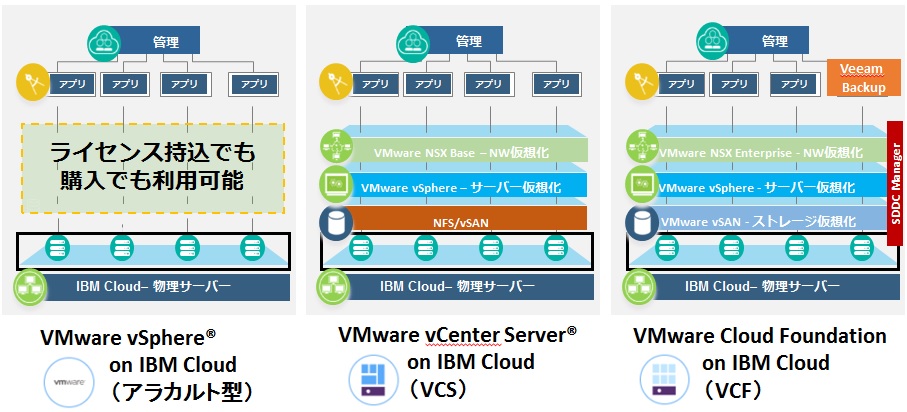
VMware on IBM Cloudは以下の3種類の構成形態から選ぶことができます。それぞれのハードウェアスペックも1種類ということはなく、複数パターンから選択することができます。どの方式もVMwareライセンスの持ち込み(BYOL)または月額課金の購入が可能です。
・VMware on IBM Cloud(アラカルト型)
- IBM Cloudベア・メタル・サーバーの豊富なラインナップから選択できます。
- この方式は手動で構築が必要ですので、オンプレでのvSphere環境構築に近いですね。
・VMware vCenter Server on IBM Cloud(VCS)
- 共有ディスク構成でのNFS接続が提供されますが、vSANも選択できます。
- vCenter、vSphere Enterprise Plus、NSX Base、vSAN を利用可能。
・VMware Cloud Foundation on IBM Cloud(VCF)
- VMware認定vSAN Readyノード構成のハードウェアです。
- vCenter、vSphere Enterprise Plus、NSX、vSAN、SDDC Manager、Active Directory を利用可能。vSANを利用したハイパーコンバージドをイメージすると分かりやすいと思います。
また、ベアメタルサーバーには最新のGPU を追加可能なので、VDI(Virtual Desktop Infrastructure)環境を構築することも可能です。
補完ソリューションが充実
災害対策、バックアップ、セキュリティ、ネットワークなどの要件を実現するために、以下のようなソリューションを追加することが可能です。VMware製品だけで要件を満たせない場合に追加できるので、実現できる構成の幅が広がりますね。

クラウドへの移行が容易
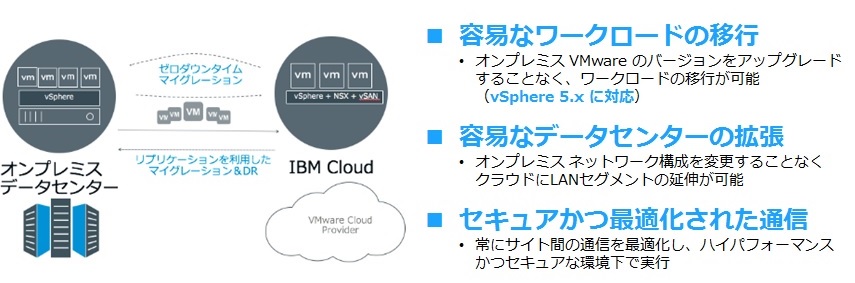
先月から日本のデータセンターでHybrid Cloud Extension(以下、HCX)が利用可能になりました。HCXは、既存のオンプレミスVMware環境のIPアドレスやルーティングなどネットワーク設定を変更することなく、IBM Cloudとの間で、簡単にマイグレーションを可能にします。
HCXには以下の特長がありますが、一番のメリットは既存オンプレミス側のvSphereバージョンが5.1以降でよいことです。クラウドに移行するためにオンプレミス側のvSphere環境をバージョンアップする必要があるとハードルが一気に高くなるのですが、バージョンアップせずに済めば移行にかかる工数も抑えることができますね。
最後に
いかがでしたでしょうか。VMware on IBM Cloudの優位性について理解いただけたかと思います。
特に注目いただきたいのは、3つの提供方式の中から選択できるVCSとVCFです。これまでオンプレミスでvSphere環境を構築するには日単位の工数がかかっていましたが、VCSまたはVCFを選択すると、たった数時間で、VMwareソフトウェアが導入済みの状態で展開されますので、構築やテストの工数を大幅に削減できると思いますので、ご検討の際にはぜひVCS or VCFをお勧めします。
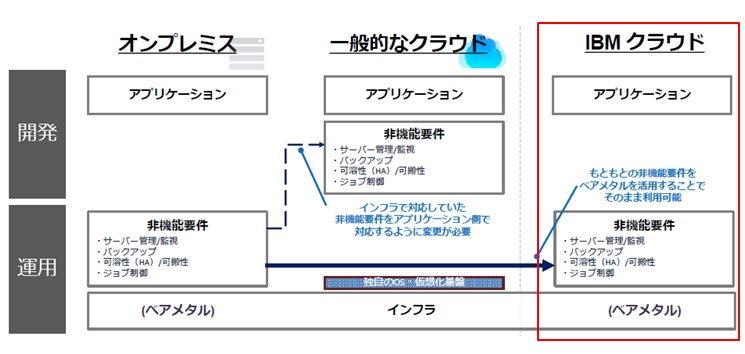
最後にまとめると、オンプレミスvSphere環境の移行先にIBM Cloudを選ぶ最大の理由は”そのまま移行”できることです。現在のスキルや運用手順を移行後も活用できるVMware on IBM Cloudを是非ご検討ください。
(参考情報)
【資料】ビジネスのためのクラウド IBMCloud のご紹介
*弊社パートナー様向けサイトのためユーザー登録/ログインが必要です。
※この記事は2018年3月27日時点の情報を元に作成しています。
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp