
こんにちは。てくさぽBLOGメンバーの山田です。
クラウドサービスのお問い合わせが少しずつ増えてきていますが、クラウド化については未だ皆さん悩まれているようです。今日はクラウド化を考えるヒントになるクラウドサービスについてご紹介したいと思います。
国内のプライベートクラウド市場
AIやIoTといった最先端のテクノロジー分野の話題が盛んな今日、SaaSのようなパブリッククラウドへの移行が加速する一方、以下のIDC Japanのレポートによると、国内プライベートクラウド市場もまだまだ成長するようです。
ここでいうプライベートクラウドとは、オンプレミス・プライベートクラウド、ホスティング・プライベートクラウド(Dedicated)、ベンダーがプライベートクラウド・サービスを提供するコミュニティ・クラウドを含んでいます。
オンプレミス・プライベートクラウドの比率は下がっていくものの、プライベートクラウド全体は2021年の支出額は2016年比5.2倍、成長率も35%以上と高い成長率が続くと予測されています。
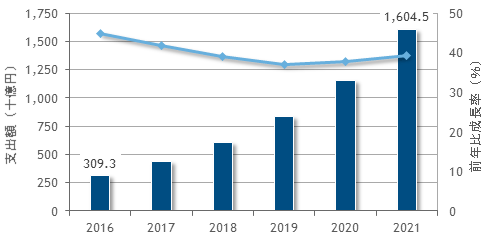
出典:IDC Japan 10・2017 国内プライベートクラウド市場 支出額予想
インフラと密接な関係があるバックアップや可用性、運用監視などの非機能要件は、クラウド化することによって、利用者側の制御範囲が変わったり、アプリケーション側で吸収できるように変更する必要があったり、というアーキテクチャーの変更検討が必要となります。これは俊敏性や柔軟性をもつクラウドを効果的に活用したいと考えている企業にとって、クラウド化検討におけるブレーキにもなっています。
既存環境はオンプレミスのまま使い続けるしかないのでしょうか。既存環境を活かしながらクラウドのメリットを享受することはできないのでしょうか。
そんなお客様には、VMware on IBM Cloudをご紹介してみてはいかがでしょう。
なぜオンプレミスをそのまま移行できるのか
クラウド化を検討する際、すべてのケースでアーキテクチャーの変更が必要になるわけではありません。下図のように変えなくてよいものはシステム更改などに合わせてアーキテクチャーを変更せず”リフト”によってクラウド上で稼働させる。また、変えた方がよいものでも、一旦アーキテクチャーを変更せず”リフト”したうえで、クラウドに最適化されたアーキテクチャーに変更して”シフト”する、という方式が考えられます。
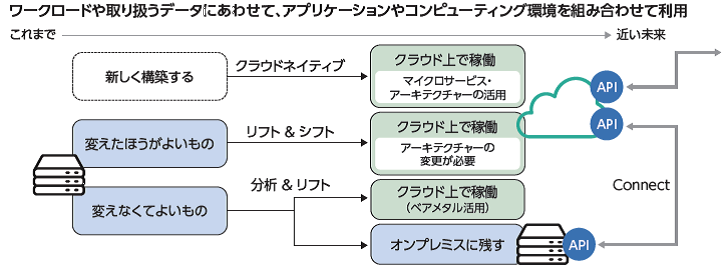
図1:IBMホワイトペーパー”VMware環境のクラウド移行を成功させるための最適解とは?”より抜粋
VMware on IBM Cloudは、ベアメタル(専用物理サーバー)上に構築された、インフラ・運用・パートナーソリューションを自由に組み合わせることができるIBM Cloudのソリューションで、オンプレミスで使用していたVMwareのサーバー仮想化ソフトやストレージ仮想化機能をサブスクリプション型で利用できるサービスです。
 図2:VMware on IBM Cloudのデプロイメント方式(IBM Cloud柔らか層本より抜粋)
図2:VMware on IBM Cloudのデプロイメント方式(IBM Cloud柔らか層本より抜粋)
上図のように、VMware on IBM Cloudでは、要件や規模に応じて3種のデプロイメント方式が用意されています。
いずれのデプロイメント方式においても利用者側に管理者権限が付与され、オンプレミス環境でのアーキテクチャーを変更することなく、”リフト”によるクラウドへの移行を実現でき、自由度の高いクラウドの恩恵を得ることができます。
特に図の左側にあるVMware vSphere on IBM Cloudでは、個別カスタマイズ型のため、オンプレミスで培った運用・ポリシー・ツール・スキルなどを活かしながら、クラウドのメリットを享受できます。
VMware on IBM Cloudの優位性
ベアメタルという専用物理サーバーを活用している点で、ホスティング型クラウドと似ている点もありますが、以下のようにクラウドならではの俊敏性や柔軟性を実現しています。一番の優位性は、移行の容易性、すなわち、vSphereの環境のVMをそのまま稼働させることができることですが、他にも以下のような優位性があります。
- 最短30分、最大でも4時間程度で環境をデプロイメント可能
- デプロイメント後のプロセッサー変更も可能
- 1時間単位での課金も可能、最低契約期間の縛りもなし
- CPUの選択肢も多く、最新機種や話題のGPU搭載マシンも選択可能
AWSやIIJなどIBM以外のクラウド業者もVMware社との提携を進め、ベアメタルの提供も始めています。
IBM Cloudのベアメタルは2005 年から提供されており多くの実績がありますが、クラウドインフラの特長と合わせ、他社と比較して以下の優位性があります。
- 要件や規模に応じた複数のデプロイメント方式を提供(図2参照)
- 日本を含む世界中40拠点以上のデータセンターで利用可能
- 各データセンター間の高速回線を無償で利用可能
- データセンターの場所が公開されており、オンプレミスとクラウド間での専用線接続が可能
- 利用者がVMwareの管理者権限を保有可能
- 既存のVMwareライセンスをそのまま持ち込める など
たとえば、多くのクラウドベンダーではVMware管理者権限がユーザー側に与えられないため、レプリケーションやセキュリティ機能の独自強化ができないなど、オンプレミスからの移行に大きな影響を与える可能性があります。
また、ここでは詳しくご説明しませんが、オープンスタンダード技術でつくられたPaaS連携やAPIによる操作性の良さもIBM Cloudの特長です。
さいごに
個別カスタマイズ型の”VMware vSphere on IBM Cloud”だけでなく、NSXやvSANの機能を素早く使いたい、VMware社認定構成で使いたい、ZertoやVeeamなどのパートナーソリューションもワンストップで提供してほしい、といった要件であれば、自動構築型の”VMware vCenter Server on IBM Cloud(VCS)”やVMware Cloud Foundation on IBM Cloud(VCF)” といったデプロイメント方式も有効です。
また、今回ご紹介したような“そのまま移行する”が実現できることにより、既存システムとクラウドの連携が進み、オンプレミスとパブリッククラウド、あるいは複数のクラウドをシームレスにつなぎたいという、ハイブリッドクラウドの要件も増えてくると思います。
昨年、VMwareとIBMが共同で発表した「VMware HCX テクノロジー」は、オンプレミスとクラウドのvSphere環境をシームレスに接続し、相互運用やアプリケーション・モビリティを実現する技術で、旧バージョンのオンプレミスのVMware環境から、最新のIBM Cloud のVMware環境に容易にワークロードをマイグレーションできますし、ゼロダウンタイムで大規模な移行が可能になります。
このテクノロジーは、IBM Cloud で先行して提供されるようです。
F5 NetworksやFortinetと協業したパブリッククラウドでのセキュリティ強化サービスも提供されるなど、企業のクラウド化を促進するサービスがどんどん発表されていますので、引き続き皆様にご紹介していきたいと思います。
※この記事は2018年1月17日時点の情報を元に作成しています。
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp