
皆さま、こんにちは。てくさぽBLOGメンバーの岡田です。
今年7月にインテル社が新しいサーバー用CPU「Xeon Processor Scalable Family(以下、Xeon Scalable)」を発表し、各サーバーメーカーからこの新型CPUを搭載したサーバーが発表されました。HPE社はGen9→Gen10、Dell EMC社は13G→14Gと順当な名称変更でしたが、Lenovo社はこれを機にサーバー、ストレージおよびネットワーク製品の新ブランドである「ThinkSystem」を発表しました。
まず全体像ですが、今回Lenovoエンタープライズ製品群は以下の3つのブランドに分けられることになりました。管理系の「XClarity」とソフトウェア・デファインド製品群の「ThinkAgile」、そしてサーバー・ストレージ・ネットワークスイッチを統合した「ThinkSystem」になります。

今回のブログでは、このうちのサーバー・ストレージ・ネットワークの「ThinkSystem」の特長について説明していきます。
1.2つのサーバーブランドの統合
これまでLenovoは旧IBM 系の「System x」と旧Lenovo系の「ThinkServer」の2種類がありましたが、今回統合され「ThinkSystem」サーバーとなりました。これまで「System x」と「ThinkServer」の使い分けに悩むこともあったかもしれませんが、今回、整理統合されたことで分かりやすくなりましたね。

以下が「ThinkSystem」サーバーのラインナップ一覧になります。「System x」と「ThinkServer」のラインナップが最新CPUのXeon Scalableを搭載してマージされました。

・ラック型2ソケットサーバーのラインナップ拡大
今回新たにラック型サーバーに2U2ソケットの「SR590」、1U2ソケットの「SR570」が追加されています。
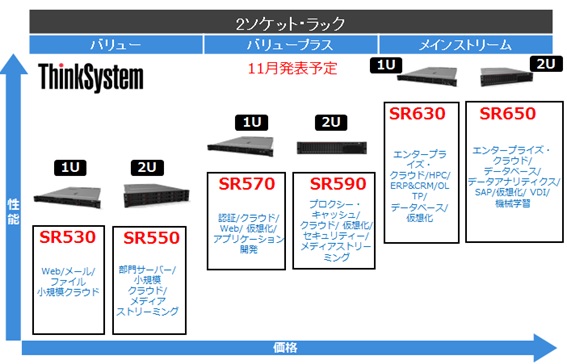
これまでLenovoの2ソケットラック型サーバーと言えば1Uの「x3550 M5」か、2Uの「x3650 M5」のどちらかでしたので、あまり選択肢がなく1Uか2Uかでモデルを決めていたのですが、今回、「バリュー」「バリュープラス」「メインストリーム」の3種類それぞれに1Uと2Uが並び、計6種類となりました。各サーバーの違いは搭載可能なCPU、メモリ、ディスク本数などが異なる点です。拡張性があまり必要でない場合に「バリュー」や「バリュープラス」のモデルを選択できるなど、要件に対してこれまで以上に柔軟にモデル選定ができるようになりますね。
・その他サーバー
タワー型、ブレード型サーバー、高密度サーバー、ミッション・クリティカルサーバーはそれぞれの現行モデルからの後継ThinkSystemサーバーがあるので、大きなラインナップ変更はありません。
・1ソケットサーバーは「ThinkSystem」ではありません
今回、1ソケットサーバーはThinkSystemに統合されずにこれまでの名称のまま販売されます。System xでは1Uラック型の「System x3250 M6」、ThinkServerでは1Uラック型の「RS160」、タワー型の「TS150」「TS460」の計4種類が該当します。
・サポートOSに注意
ThinkSystemサーバーではWindows Server 2008R2やESXi 5.5など、System x がサポートしている一部の古いOSをサポートしていません。ですので、これらのOSを利用する必要がある場合は、System x での導入を検討ください。
*サポートOSの詳細は各サーバーのシステムガイドをご確認ください。
2.ストレージ DSシリーズ/DBシリーズ
・Lenovo StorageはSシリーズ2種類(S2200/S3200)がこれまで販売されていましたが、ThinkSystemサーバーと合わせて更新され、DSシリーズとして新たに3種類(DS6200/4200/2200)が発表されました。

また、SANスイッチもこれまでのBシリーズ(16Gbps対応)からDBシリーズという32Gbps対応のSANスイッチにラインナップが更新されました。
大規模向けSANダイレクターのDB400D/800DはBシリーズ時にはなかったラインナップで、今回新たに追加されました。

なお、ストレージVシリーズ(V3700v2、V5030、V5030F)は今回、ThinkSystemに統合されていませんので、引き続き併売されます。
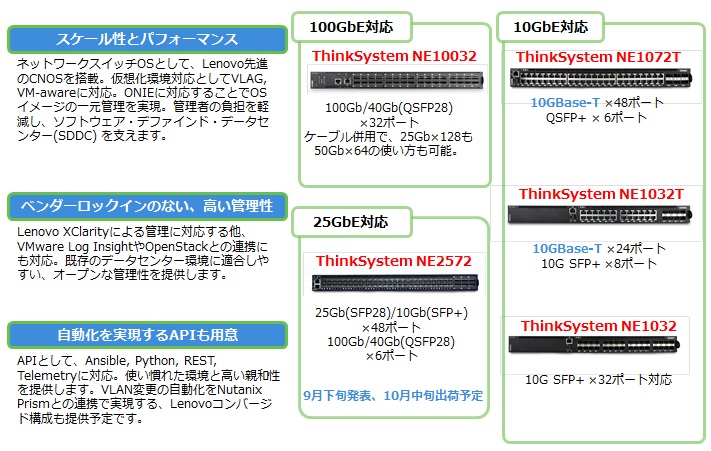
3.ネットワークスイッチ NEシリーズ
・ThinkSystemのネットワークスイッチはNEシリーズとして計5種類が発表されました。
これらのスイッチには、CNOS(Cloud Networking Operating System )という新しいネットワークOSが搭載されています。
このCNOSは、スケール性、簡単さ、オープン性、各種スクリプトによる自動化の実現に向けて開発されました。
まとめ
いかがでしょうか。IBM時代からおなじみの「System x」サーバーはこれまで順当にM2→M3→M4→M5と名前を更新し続けていましたが、1種類を残しとうとう無くなります。昔から関わっていた者としては寂しいですが、1つに統合されてラインナップも拡充したThinkSystemは、お客様の選択肢も大きく広げてくれると期待しています。1ソケットサーバーやストレージのVシリーズなどThinkSystemに含まれなかったものもありますので、少し分かりづらいと思われるかもしれません。選定に迷ったら弊社までぜひご相談いただければデザインからモデル選定など幅広くご支援させていただきます。
この記事に関する、ご質問は下記までご連絡ください。
エヌアイシー・パートナーズ株式会社
技術支援本部
E-Mail:nicp_support@NIandC.co.jp