この記事のポイント
Watson API によって、急速に成長する 第3次 AI (人工知能)ブームの波に乗り遅れることなくビジネスに参入できる機会が広がっています。
当ブログは、企画部の担当が改めて Watson ビジネスについてその可能性を考え、「今だからこそ利用するタイミングである」と判断した理由について記載します。
主に営業、企画、マーケティングやマネージャークラスの方を対象として記述しております。
内容は担当者の個人的な見解が含まれております。また、急成長している市場とテクノロジーですので、最新の情報はリンクのソースを見て確認いただきますよう予め了承ください。
先に結論:「今こそ、Bluemix で Watson 日本語版を使うべき4つの理由」
1.IBM Watson の日本語環境は7月から、大きな縛りがなくなり、より利用しやすくなった
2.Watson は、コグニティブ・システムを実現するための要素を Web API として提供している
3.API エコノミーは 260 兆円を超える市場に成長する予測がある
4.Bluemix はクラウドサービスのデパートのような存在でありながら、すぐに利用開始可能である
上記4つの理由によって、技術者だけでなく、ビジネスを拡大させるミッションの営業、企画、マーケティングの方も Bluemix を評価・利用しない理由が見当たらないという結論に至りました。
1.4.については、弊社のビジネスパートナー様向けに、”MERITひろば” にて詳細をご紹介しています。
日々進展するWatson API(日本語対応)ここをチェックしよう
「え?12 個でしょ?13 個なの?」
弊社の企画部のリサーチメンバーにおいても、今日(2017年7月1日)現在での Watson API の日本語環境リリースは 13 個か?12 個か?で意見がわかれていました。
正解は 12 個。IBM Bluemix カタログの Web サイトで公開されています。ログインしなくとも見ることができるのでまずはページを開いて俯瞰してみましょう。
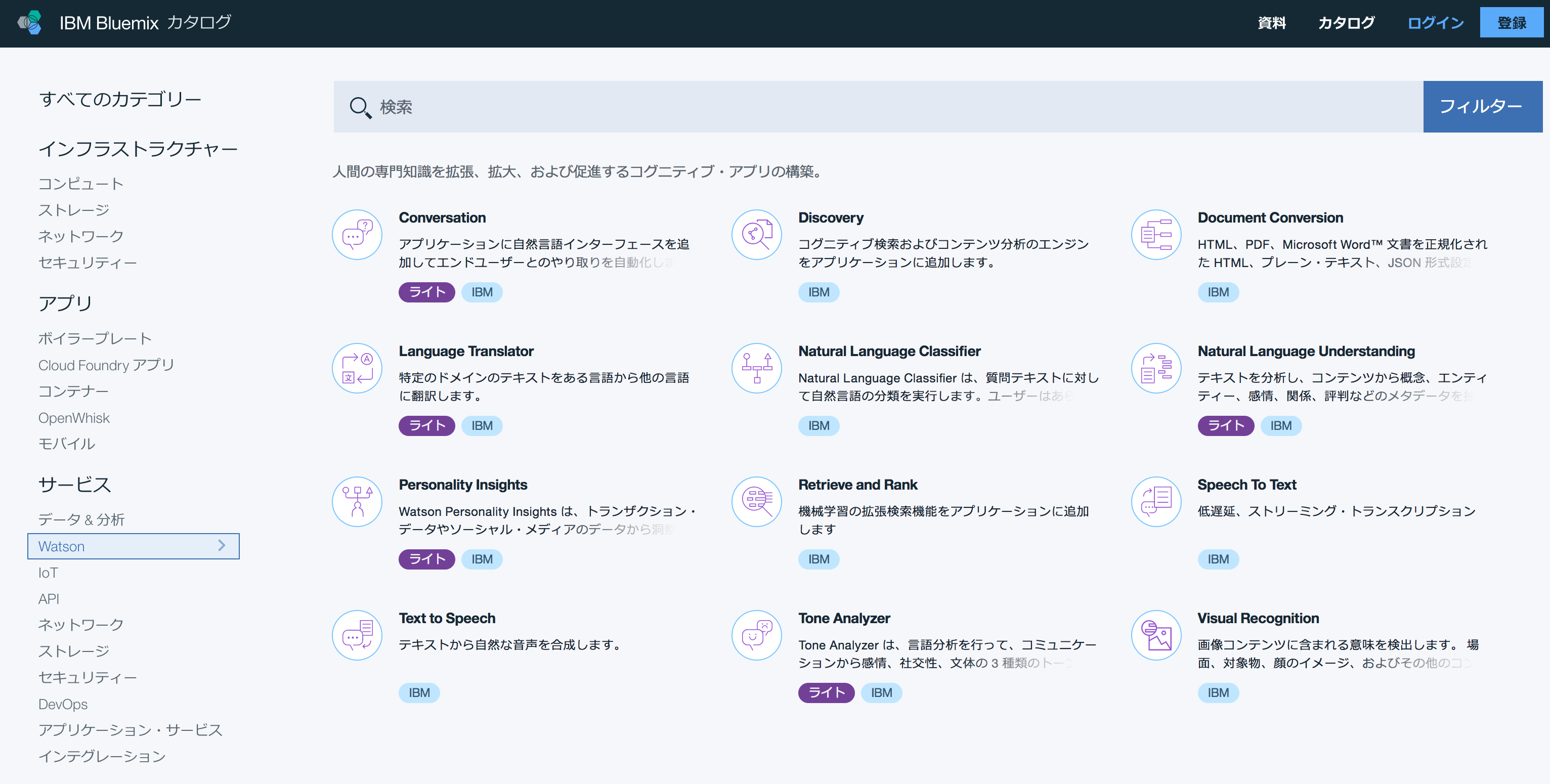
13 個だと認識していたメンバーは IBM WatsonのDeveloper Cloudのサイトを見ていました。
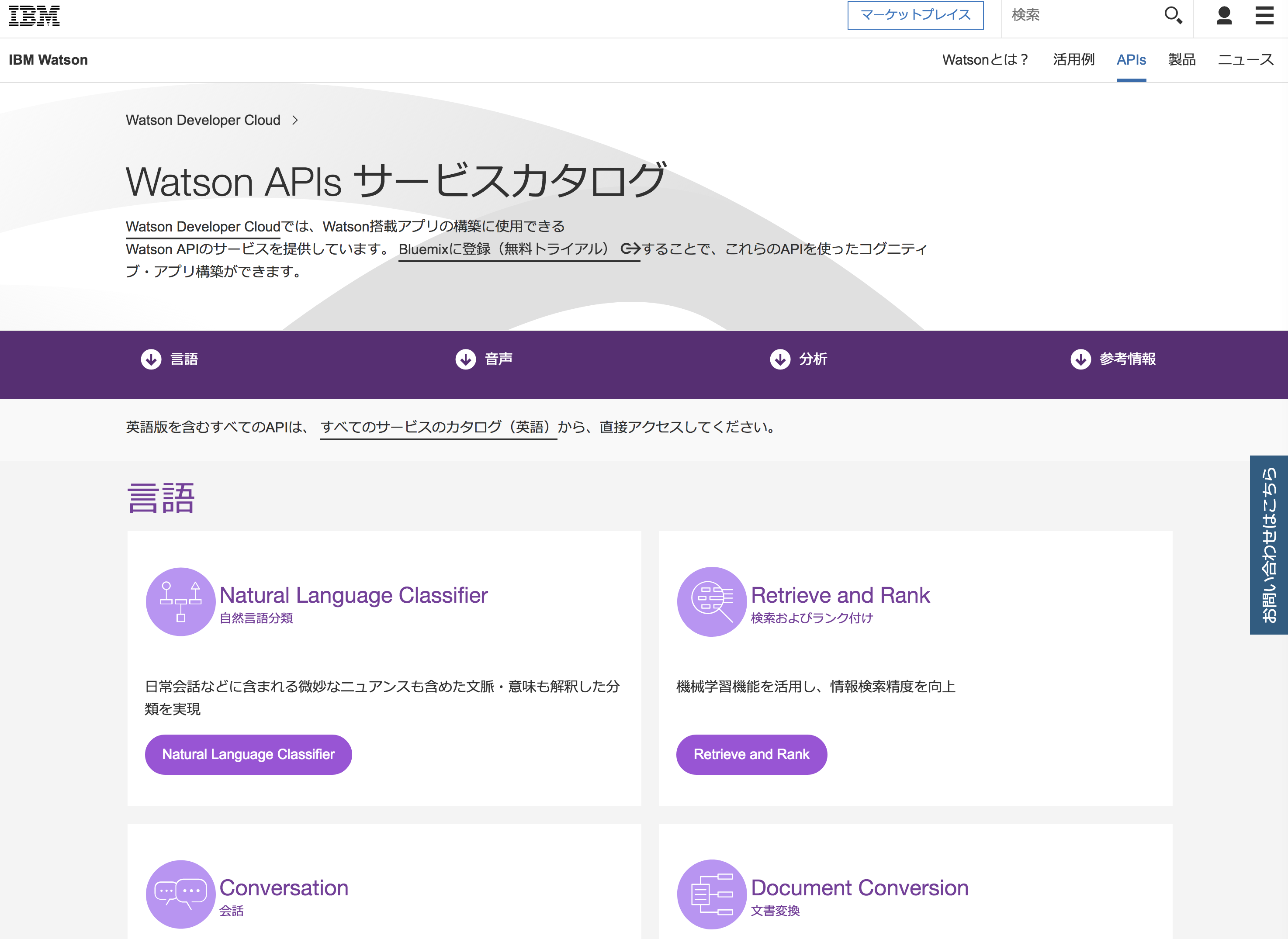
前者は IBM Bluemix のサイト、後者は IBM マーケットプレイスのサイト。マーケットプレイスはリリースされて間もないのですが、ある API は IBM 以外の会社が開発し、カタログとして掲載しているので数に違いが出ました。
今後、マーケットプレイスの API は増えていく見込みです。
12個どころではない、実は以前からフル機能使えていたBluemix
英語 Web サイトではもっと多くの APIs が公開されており、英語アレルギーが無い人々、開発者などはフル機能の恩恵、先行者利益を得ていたことでしょう。
しかし、焦らなくとも大丈夫です。この市場はまだまだ今後成長することが予想されており、この記事を読んでからすぐに「まずはやってみよう」という気持ちで進めてください。
手順や契約など不明な点がある方はお気軽にお問い合わせフォームからご連絡ください。弊社ビジネスパートナー様は担当がご説明差し上げます。
日本語の IBM Bluemix サイトに掲載されている API もまだ完全に日本語対応していないのですが、日々進展しております。
260兆円市場? そもそも API(エーピーアイ)とは?
アプリケーションプログラミングインタフェース(API、英: Application Programming Interface)とは、ソフトウェアコンポーネントが互いにやりとりするのに使用するインタフェースの仕様である。(出典:Wikipedia)
この API はWeb API のことを示しており、ソフトウェアの一部を Web 上に公開することによって、誰でも外部から利用することができる仕組みです。
例えば、Instagram (インスタグラム)のアカウントを作成するときに、Facebook アカウントでそのまま利用することができますが、他のアプリ、サービスのアカウントで認証する仕組みも API を使っているのです。アプリケーション同士が連携でき、開発側は API を使うことでその機能を自社で開発する必要がないという大きな利点があります。
この API を提供する側の市場は「APIエコノミー」と呼ばれ、2018年には 260 兆円市場に成長するという予測もあります。
では、API 提供者しか利益を享受出来ないのかと言えばそうではありません。
API を組み合わせる、データを提供する、新たなサービスを作るといった”付加価値”をつけることで新たなビジネスを創出できる点が重要なのです。
海外で人気の API をローカライズ(翻訳)してサービス提供するだけでも立派なモデルとなり得ると思います。
また、この2年ではチャットボットを使った会話形のサービスも数多く生まれてきましたが、 Conversation という Watson API の日本語版を使うことでチャットボットの開発は効率化され、貴社の資産(データ)があらたなビジネスにつながる可能性が高まっています。
スタートアップや Web 系のベンチャーは当たり前のように使っている API を是非、貴社のビジネスに取り入れてみてはいかがでしょうか。
2017年7月版 APIを使ったデモサイトを見てみよう!
百聞は一見にしかず、実際に Watson API デモを見てみましょう。12個の API から今回は 2 つの API デモサイトをご紹介。
その1:画像から意味を検出しちゃう! 「Visual Recognition」
この API はその名のとおり、画像を判別する機能で、ユーザ独自の画像判別モデルを手軽に作成できます。
Web 上で公開されているいくつかのデモの中で、日本情報通信株式会社の Bluemix デモサイト に記載されている記事を紹介します。
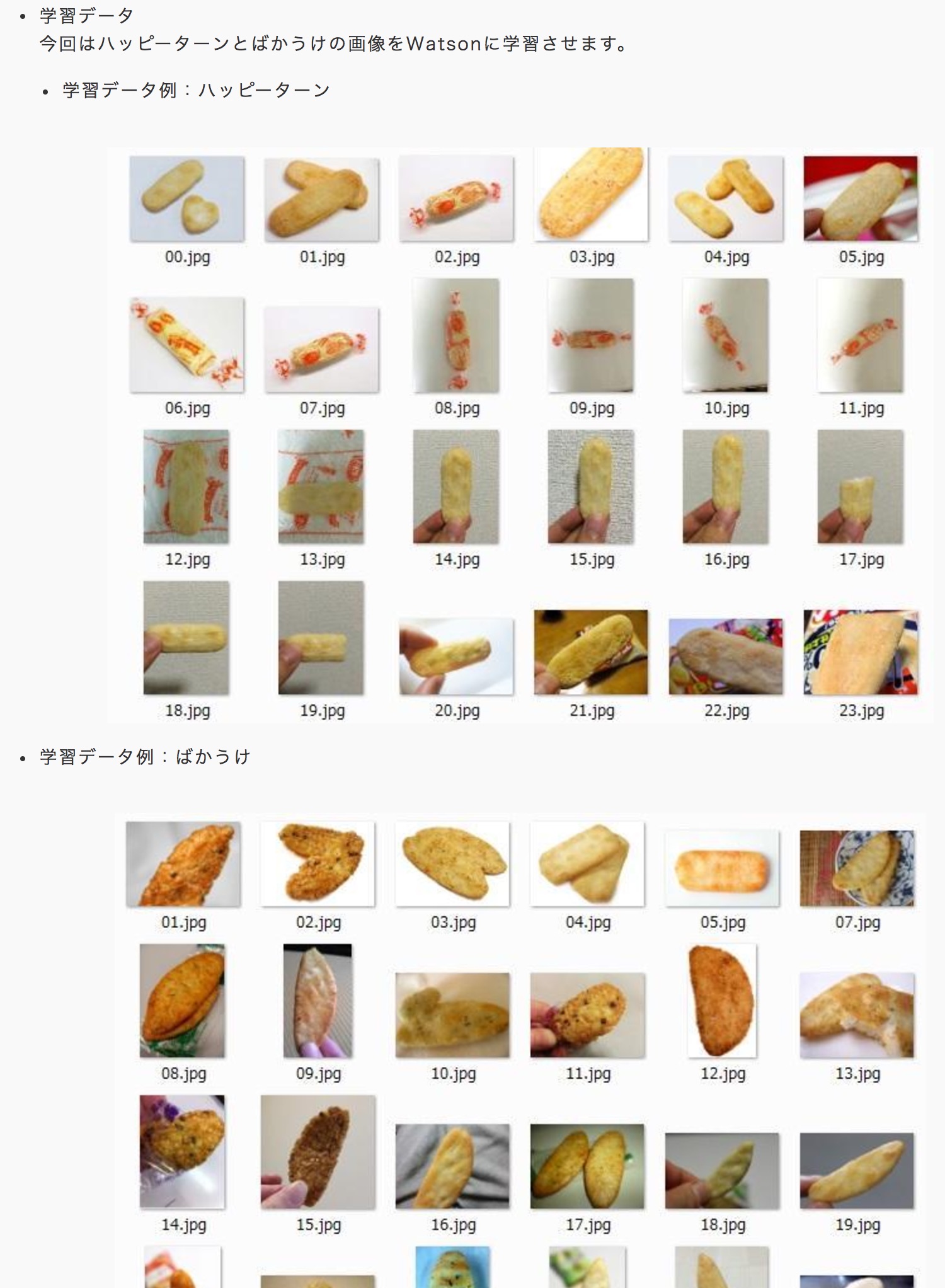
「ハッピーターン」と「ばかうけ」を判別することが出来る?

日本人にピッタリの良いデモですね(笑)。判定させるために、ハッピーターンとばかうけの画像をWatsonに学習させています。
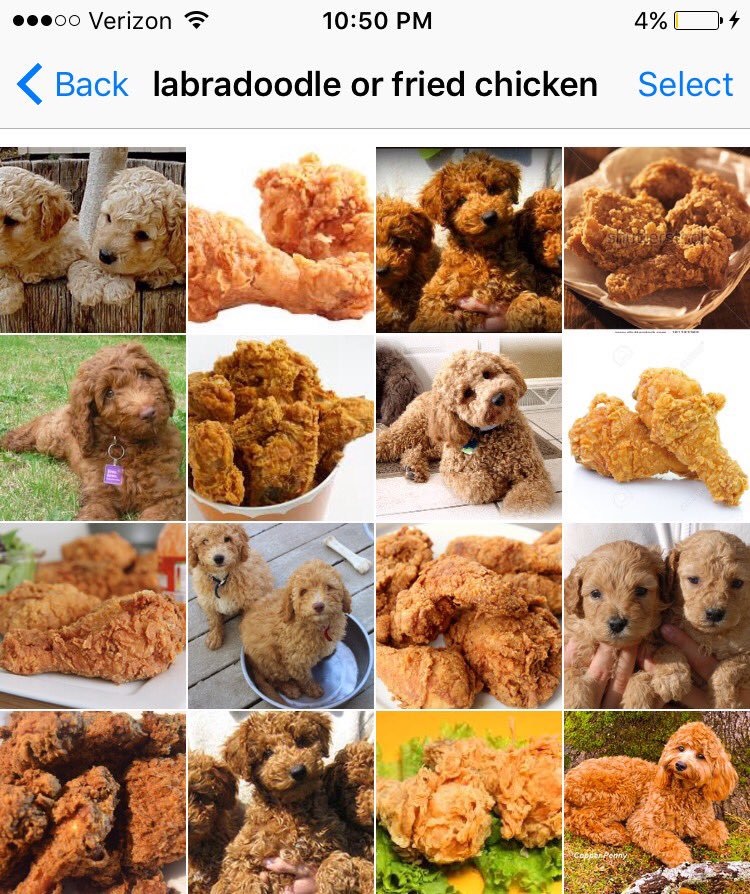
また、技術サイト Qiita では、X(旧称:Twitter)で話題になった「ラブラドールとフライドチキン」の画像を Visual Recognition API で判定させてみたブログもありす。
そこで、私も使ってみました。デモサイトは英語版ですが、画像系なので抵抗ありません。
エンジニアではないため、試しに画像を Upload しただけ、10 分で体験しました。
サイトは冒頭で紹介した IBM Watson Developer Cloud の英語版サイト。
サンプルの画像をクリックするか、自分で画像をアップロードしてみよう!とのことで、この画像をアップロードすることにします。

そうです、MERITひろば のロゴです。
学習をさせていない Watson に判定さてみます。ロゴ画像を指定し、待つこと5秒。結果がこちら。
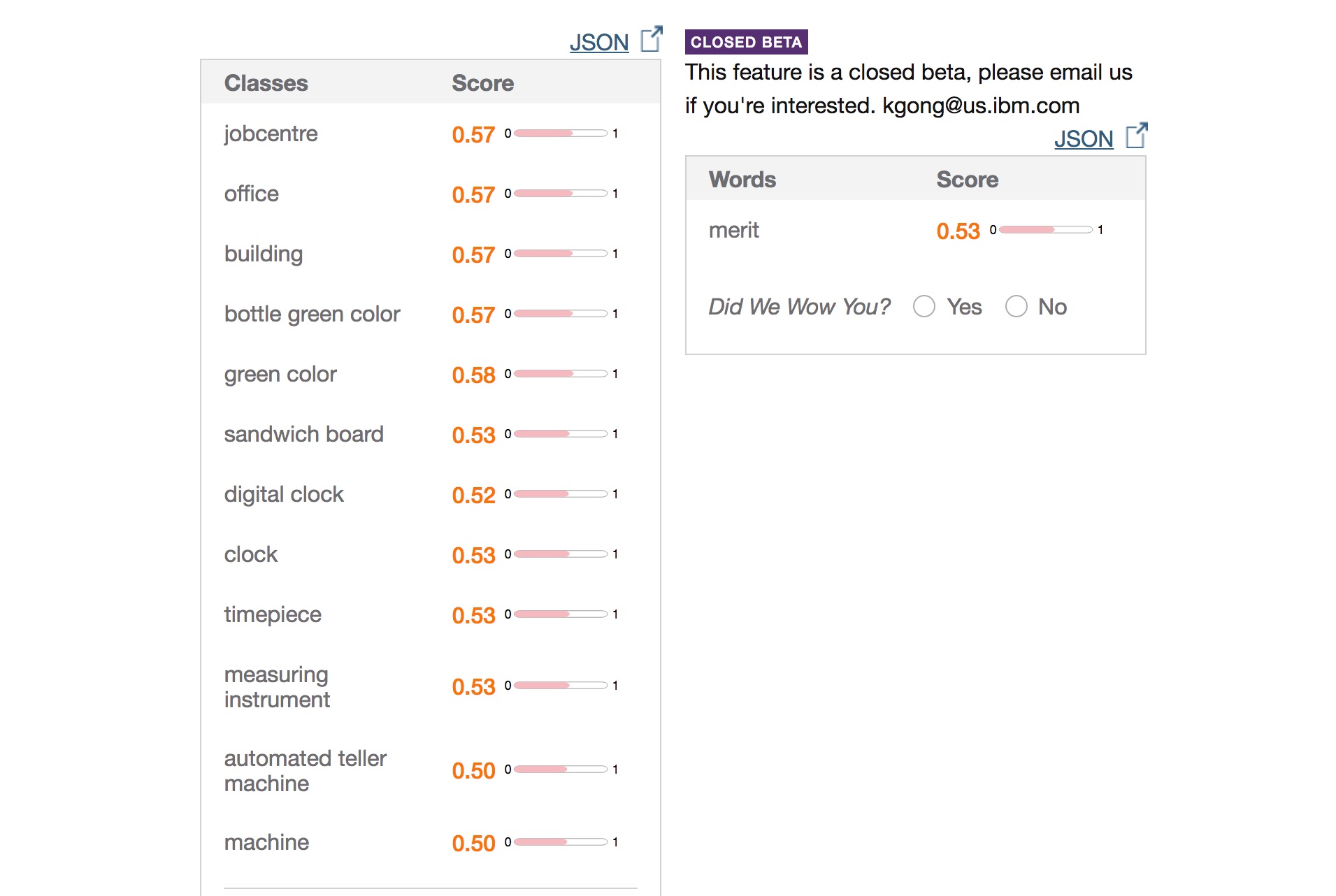
Watson が MERIT ひろば のロゴから読み取った意味は「Jobcentre」 0.57、「Office」 0.57と続きます。Watsonは正解に対する確信度を0~1の数字で表しているので、0.5をちょっと超えていますがが「うーん、たぶんJobcentre?」という感じでしょうか。
ハッピーターンの時のように学習させてませんから無理もありません。
ところで、jobcentre とは何でしょうか。どうやら、イギリス版ハローワークのようです。
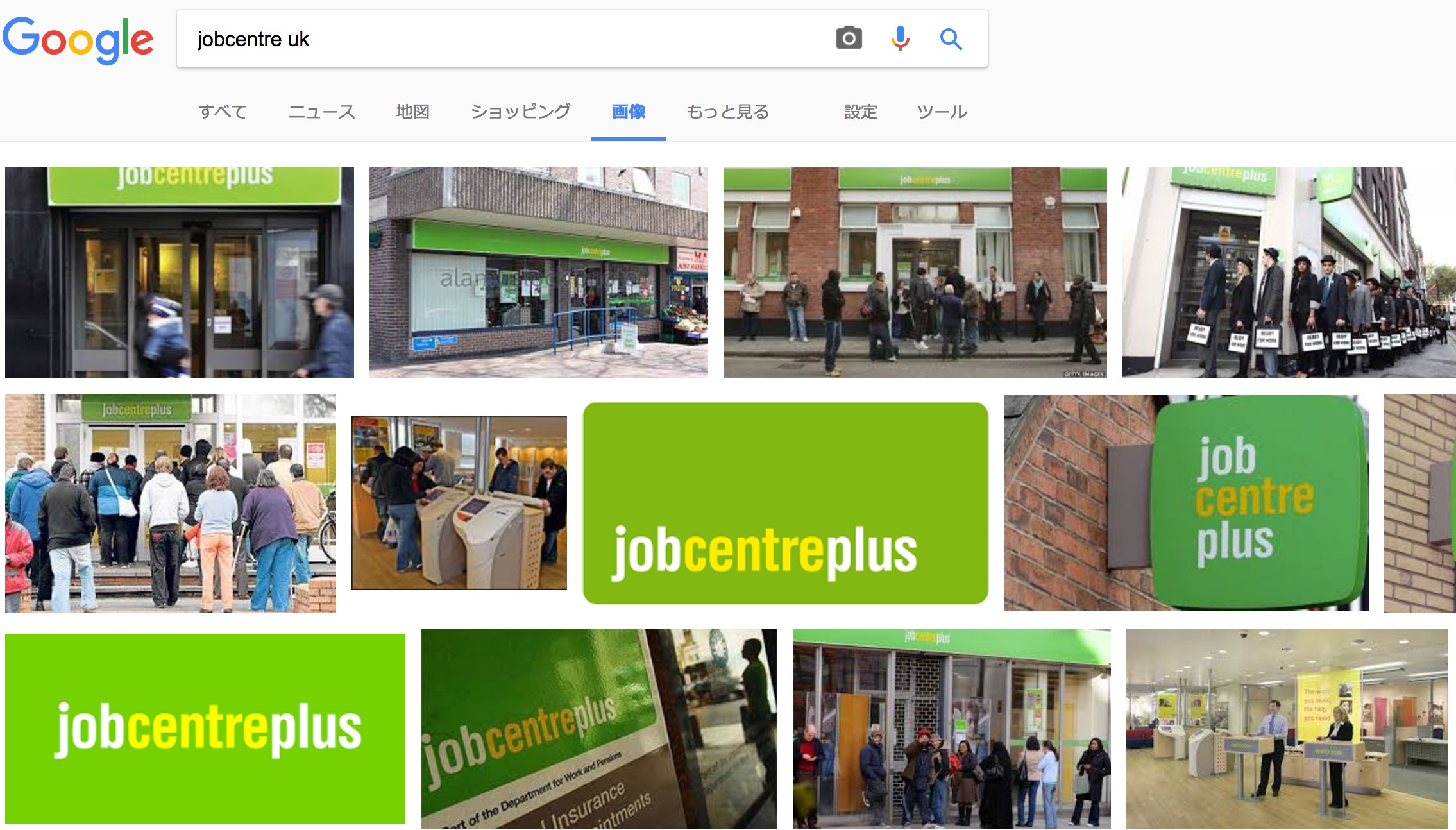
Google は似ている画像を検索していますが、Visual Recognition API はネット上を検索するのではなく、その画像の意味を考えたのですね。
今後は「あの MERITひろば でしょ?」と Watson に言わせたいと思いました。
その2:テキストから筆者の性格を推定しちゃう「Personality Insights」
次は、言語分析をして、文章を書いた人の思考や性格を推定する API です。
では、早速このブログ記事のここまでの文章をコピペして診断します。・・・約 3,400 文字ですが、待つこと2秒で結果がでました。
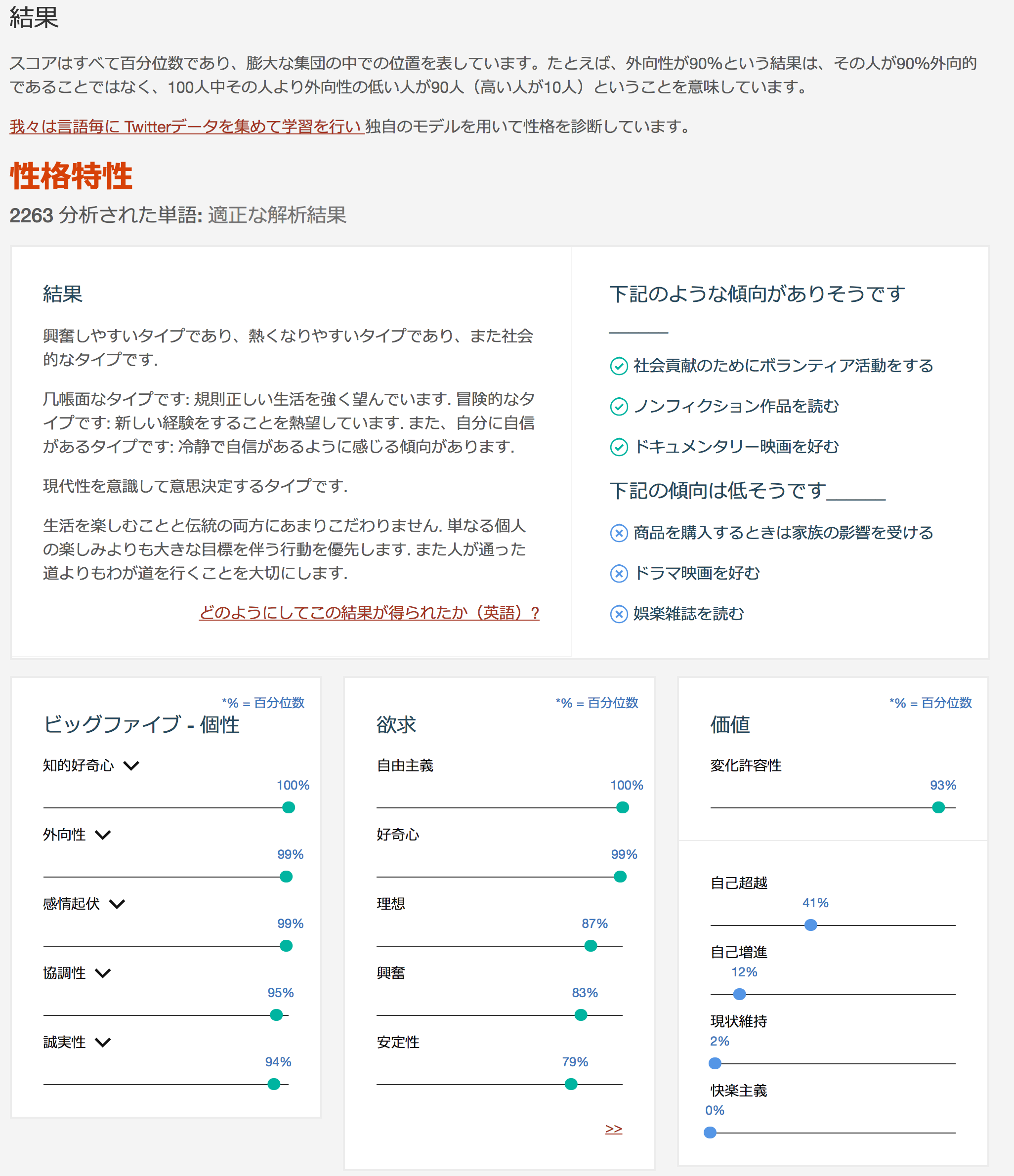
かなり攻めの姿勢がある人物ですね(笑)
右上に記載されている「下記のような傾向がありそうです」については、具体的ですのでわかりやすく、正直あたっていると思います。
X(旧称:Twitter)アカウントを入力すると過去のツイートから性格判断をしてくれます。
さて、この API をビジネスに展開するにはどのようなアプローチが考えられるでしょうか。
例えば、人事・採用の現場で SNS のデータから人物の特性を見る・・・というのは序の口で、特定の著者の文章を学習させ、校閲をWatsonが実施し、「この著者はこのような表記を使わない。もしかして◯◯では?」という示唆をしてくれるかも知れません。
もちろん、商品のマーケティングで SNS を分析して消費者の反応を解析するのにも役に立ちます。「これヤバくない?」がどちらの意味のヤバイなのかは前後の会話や状況、その人の過去のヤバイの使い方によって反対できるのかも知れません。
自社でどのように Bluemix 、Watson API を検証し、ビジネスにつなげていけばよいか
ここまではテクノロジーの可能性を見てきましたが、いざ自分たちのビジネスにつなげるにはどのようなアプローチが必要でしょうか。
使ってみる!という最初の一歩を踏み出すには、まずは自分(自社)の得意な領域で評価してみるのが良いと思います。
例えば、IBM の特約店など、旧来から IBM 製品を販売してきた企業の場合を考えてみます。
会社では Notes を利用していますが、Notes に蓄積されている文書データの解析に Watson を利用してみることを検討したとします。そうです、共有 DB などの膨大な文書が存在しているはずです。
これらは、カテゴリに分けて整理されていると思いますが、探す時だけでなく、文書を作成し登録する際にも「どのカテゴリが適しているか」に悩んだことはありませんか?
テキスト解析を活用すれば、ユーザは文章を Notes に放り込むだけで、Watson が文書の中身をみて、適切なカテゴリに配置してくれるという仕組みが考えれます。
これによって、社員の生産性があがる可能性があります。
このようなナレッジを社内に作ることで、自社の顧客の製造業に対して、製品の利用者のデータが膨大に集まっているが活用できていないケースを見つけ、サービスを構築することにつながるかも知れません。(もしくはデータを集めるビジネスモデルを提案できるかも知れません)
最後に
IBM Bluemix、IBM Watson API (日本語対応)について、2017 年は「まずは使ってみる」というビジネスの準備期間として取り組んでみてはいかがでしょうか。
この Web サイトを運営しているメンバーの一人が「日々投稿しているページのサムネイル画像の選択が大変なので、Watson に自動選定してほしい!」と言っていました。
今は人間がやっているが、自動化できるのではないか? 自動化されると助かる!という領域こそが Watson ビジネスの切り口になると思います。
若手のエンジニアや Web サービスを企画したい人に Watson API を使ったコンテストを実施し、その可能性を検証してみるものも良いでしょう。
API やクラウド、オープン系の技術をビジネスにつなげるきっかけは意外なところにあるかも知れません。
そのきっかけ作りをお手伝いします。お気軽に弊社までお問い合わせください。
ご案内
7月27日、8月31日に日本 IBM が主催となる IBM Watson 実践セミナーが東京で開催されます。ビジネスパートナー限定のセミナーです。
詳細はMERITひろばの案内ページをご覧ください。