
近年、企業の DX推進は活発化し、それにともない企業の IT環境も急激に変化・複雑化しています。
この変化に対応するセキュリティ対策のキーワードとして今、注目されているのが「ゼロトラスト」です。
本コラムでは、ゼロトラストのセキュリティ対策について解説。
さらに、多要素認証によりユーザー・アクセスを安全に簡素化することで、ゼロトラスト・セキュリティを実現する「IBM Security Verify」をご紹介します。
Index
- 今、セキュリティ対策の強化が注目されている理由
- セキュリティ戦略は「境界防御」から「ゼロトラスト」へと変化
- まず企業がすべきことは「守るべき要素」の洗い出し
- 情報セキュリティ対策強化の第一歩は「多要素認証」の導入から
- 多要素認証によりユーザー・アクセスを安全に簡素化するIBM Security Verify
- この記事に関するお問い合わせ
- 関連情報
今、セキュリティ対策の強化が注目されている理由
近年、DX に取り組んでいる日本企業の割合は急上昇し、クラウドシフトや場所を問わない柔軟な働き方が浸透しつつあります。さらに、2019年末から世界的に拡大した COVID-19 のパンデミックをきっかけに、日本企業のテレワーク実施率も急激に伸長しました。
これにともない、在宅勤務で使用する PC や社外で使用するモバイル端末、IoTデバイスを狙った攻撃の増加やクラウド環境での管理の煩雑さや設定ミスなど、新たなセキュリティリスクが増加しています。
企業はこれまでも既にセキュリティに関する備えをしてきました。しかし、急増する新たなセキュリティリスクに対応するためには、これまでのオンプレミスを前提とした現行の ITインフラや、「境界防御」を前提としたセキュリティ対策では、限界があることが指摘されています。
これらを背景に、今、企業は再度セキュリティ対策の見直しと強化をする必要に迫られているのです。
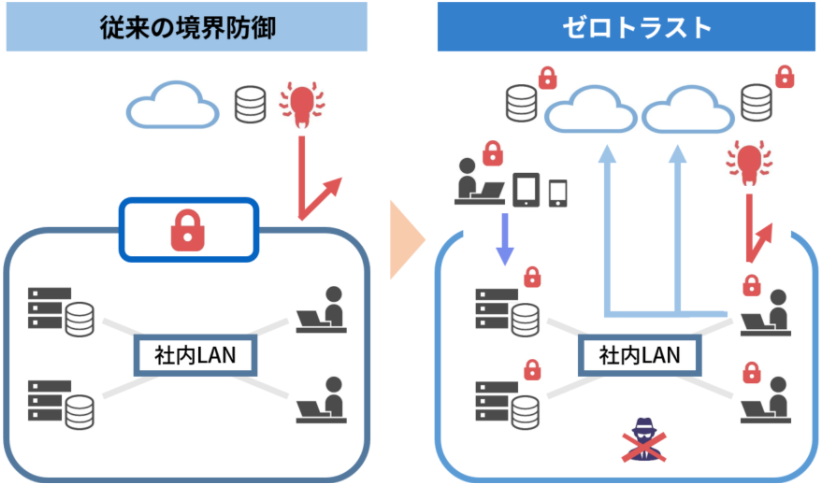
セキュリティ戦略は「境界防御」から「ゼロトラスト」へと変化
これまでのセキュリティ対策は、境界を設置して守るべき領域の「内部」と危険が潜む「外部」とに環境を分けて、その境界の「内部」に如何に侵入されないかという防御策が主流でした。
しかし、テレワーク環境で仕事をする人や Web会議、社内システム、コラボレーションなど、クラウドサービスの活用が増加した今、これらを利用するユーザーのアクセス場所やデータの保管場所は、境界の「外部」へと移っています。
そのため、従来の VPN接続を前提とした「境界防御」のセキュリティ対策だけでは、ランサムウェアやフィッシングなど、脆弱性を利用した標的型攻撃への対応は困難となり、被害発生時の影響範囲も拡大してしまいます。
この課題への対応として、今、もっとも注目されているキーワードが「ゼロトラスト」です。
「ゼロトラスト」とは、新たな発想に基づくセキュリティ対策の考え方で、防御の境界を定めません。同時に「内部=安全」「外部=危険」という承認ではなく、「信用せず、常に検証する」ことを基本とします。
つまり、ITシステムを利用するユーザーや場所、デバイスなどを無条件では信用せず、守る対象を定義し、それぞれについて認証を行い、アクセス権を設定することで、重要情報の安全を確保していくというセキュリティ対策の考え方です。
セキュリティ戦略も急速な変化への機敏な対応を余儀なくされている今、企業が見直しを迫られているのは、この「ゼロトラスト」へのシフトだといえます。
まず企業がすべきことは「守るべき要素」の洗い出し
「境界防御」から「ゼロトラスト」へとセキュリティ戦略のシフトが急がれているとはいえ、すべての対策を一気に始動することは、人的リソースの面でもコストの面でも困難です。
では、企業は何をするべきなのでしょうか?
まず企業がすべきことは、自分たちが守るべき要素を洗い出すことです。「何から始め、どう守るか」を正しく理解するためにも、守るべき要素を洗い出すことがなにより重要です。
次に必要なことは、洗い出した要素の中から、自社にとってより効果的に対策を始めるための優先順位をつけることです。
ゼロトラストにおいて、企業にとって重要なもの、および守らなくてはいけない要素と対策例として、主に以下が挙げられます。
| 人 |
|
| 認証情報 |
|
| エンドポイント (PCやモバイル端末など) |
|
| アプリケーション |
|
| データ |
|
情報セキュリティ対策強化の第一歩は「多要素認証」の導入から
クラウド利用が広がりテレワークも普及すると、セキュリティ対策を施さなければならない境界は広く複雑になります。
これに対して、「知っている人なら誰でも入ることができる」ユーザー名とパスワードだけでは、「本当に当社の社員なのか?」「特定の許可された人間なのか?」が判別できません。ログインした人を確実に判別する必要があります。
これに対し、非常に強固な認証システムとして注目されているのが「多要素認証」です。
「多要素認証」とは、ITリソースを利用するユーザーがユーザー名とパスワードを入力した後、登録された携帯電話に SMS でワンタイムパスワードを送ってくる「二要素認証」や、人の眼・指紋・静脈など、本人しか持ち得ない肉体的な要素を活用して認証する「生体認証」を複合的に組み合わせて確認することです。
これにより、特定の人固有の情報を利用して追加で認証を行うため、非常に効果的に「認証基盤の強化」を実現することができます。
「認証基盤の強化」が実現すれば、その後工程にあるアクセス制御やエンドポイント・セキュリティ対策もシンプルかつ容易になります。したがって、「ゼロトラスト」シフトのセキュリティ戦略の第一段階として、この「多要素認証」の導入から始めることをお勧めします。
多要素認証によりユーザー・アクセスを安全に簡素化するIBM Security Verify
企業内外のすべてのユーザーとデバイスを、オンプレミス/クラウド上のあらゆるアプリケーションに安全に接続し、単一のプラットフォームでシンプルに管理できるのが「IBM Security Verify」です。
「IBM Security Verify」は、IBM が約20年間にわたりオンプレミス版で培った技術と実績をクラウドサービスとして展開し、2021年4月からは日本のデータセンターからサービス提供を開始しています。
これにより、オンプレミス環境はもちろん、ハイブリッド/マルチ・クラウド環境に対応したスマートID を日本のお客様に提供できるようになりました。
Security Verify の最大の特長は、AI を搭載したリスク・ベースの多要素認証による「IAM (ID・アクセス管理) プラットフォーム」を提供していることです。
これにより、「誰が何にアクセスできるべきか」を決定するために AI の優れたコンテキストを活用することができるだけでなく、モダナイズ済みのモジュール形式の IAMプラットフォームであるため、容易に導入することが可能です。
また、モバイルを含む各種デバイスでシングルサインオンをすぐに始められるだけでなく、それぞれの企業のニーズに合った API優先アプローチを採用し、脅威管理とインシデント対応を包括するセキュリティワークフローと統合することもできます。
IBM Security Verify は、適応型アクセス制御機能によって、「多要素認証をどのタイミングでユーザーに求めるか?」について、コンテキストを用いた判断や実績のあるアルゴリズムの活用など、コグニティブを活用したリスク判断を行うとともに、各種攻撃への対応を実行してセキュリティの強化と利便性を両立させます。

さらに、アダプティブ・アクセス機能 (適応型アクセス制御) を搭載することで、セキュリティの強化と利便性を両立できることも Security Verify の大きな魅力です。
「ID のプロビジョニング/デプロビジョニング」、「アクセス権の正当性の確認」、「アカウントの突き合わせ」など、エンドツーエンドのユーザーライフサイクルを管理することで、「お客様のモバイルの生産性を妨げる障壁の解消」「リスクを認識する認証の確保」「すべてのプラットフォームへのアクセス管理」および「ID の正しい管理」を一括に実現します。
エヌアイシー・パートナーズでは、IBM Security Verify についての情報提供はもちろん、パートナー企業様がエンドユーザ様に対して行うご提案のサポートも行っております。
まずは、エヌアイシー・パートナーズにご相談ください。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- IBM Security Verify (製品情報)
– 企業内外のすべてのユーザーとデバイスをオンプレミス/クラウド上のあらゆるアプリケーションに安全に接続する単⼀のプラットフォームです。
【外部ページ】